cs224n lecture 3 note: more word vectors
1. 回顾word2vec
上一节只讲了最基本的word2vec,没有涉及到应用中的trick,在这节课上,通过回顾word2vec的实现,来引入两个trick。
-
1. 构建词语与词向量的hash表
既然在SGD中,每次只有窗口内的单词的梯度需要更新,那么可以建立单词与词向量的hash表,每次只更新窗口内单词对应的参数。
-
2. 负采样
将每次过程看做是分类任务,窗口内的为正例,窗口外负采样得到的为负例,计算与参数更新过程都针对窗口内的词和负采样得到的词,可极大地提高运算效率,避免了每次词表大小级的指数运算。损失函数变为:
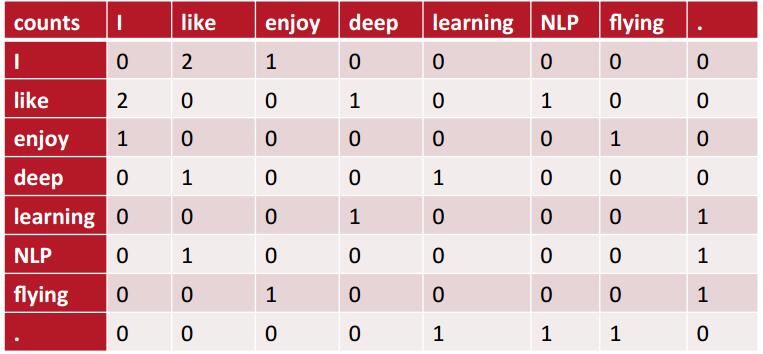
2. 基于窗口的共现矩阵方法
我在上节的笔记中有写到,word2vec是一种预测模型,它利用了窗口内的信息做出预测,最大化预测概率;同样是利用了窗口,共现矩阵法利用的是窗口内的词语共现信息,是一种基于统计的方法。这种方法很直观,想要捕捉词语之间的关联,词语的共现信息是个十分有效的方法,主题模型中,通常利用到这个信息。不过,要注意的就是无用高频词的影响,比如the, a, … 它们的共现信息是无用的。有了共现矩阵,也就自然有了词向量。
-
局限性:
- 当出现新词的时候,以前的旧向量共现信息,维度都需要改变
- 高维度
- 高稀疏性
-
解决办法:
将高纬度稀疏向量转换成固定的低纬度的稠密向量(eg: svd, pca…)
-
改进:
- 限制高频词的频次,或者干脆停用词
- 根据与中央词的距离衰减词频权重
- 用皮尔逊相关系数代替词频
-
效果:
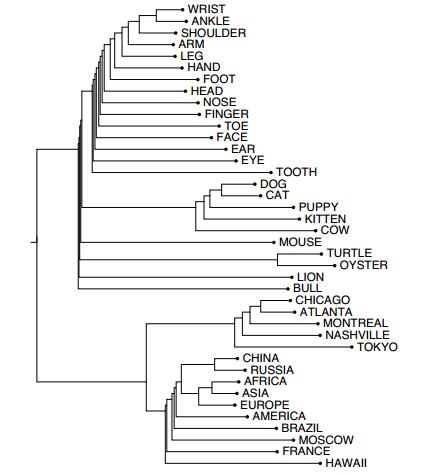
-
svd的问题
- 计算复杂度高
- 不方便处理新词和新文档
- 与其他DL模型训练思路不同
-
统计模型与预测模型比较
这些基于计数的方法在中小规模语料训练很快,有效地利用了统计信息。但用途受限于捕捉词语相似度,也无法拓展到大规模语料。
而NNLM, HLBL, RNN, Skip-gram/CBOW这类进行预测的模型必须遍历所有的窗口训练,也无法有效利用单词的全局统计信息。但它们显著地提高了上级NLP任务,其捕捉的不仅限于词语相似度。

3. 两种模型思想的结合-Glove
目标函数:
其中:
为什么说它兼顾了两种思想呢?
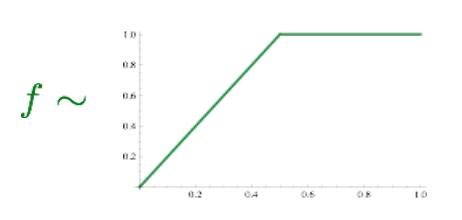
我们来看公式,公式里的u和v是如下图所示的共现矩阵中的行、列向量,物理意义是最小化 词对内积(相似度) 与 真实共现信息 之间的距离。而 f 则起到限制高频词的作用。
最后:
相加来自实践后的结果。
4. 评测方法
有两种方法:Intrinsic(内部) vs extrinsic(外部)
Intrinsic:专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,但不知道对实际应用有无帮助。有人花了几年时间提高了在某个数据集上的分数,当将其词向量用于真实任务时并没有多少提高效果。
Extrinsic:通过对外部实际应用的效果提升来体现。耗时较长,不能排除是否是新的词向量与旧系统的某种契合度产生。需要至少两个子系统同时证明。这类评测中,往往会固定预训练向量(即为static状态,不参与参数更新)。
比较有效的方法,从计算上来讲,有如下方法:
- 计算向量cosine值,即相似度
-
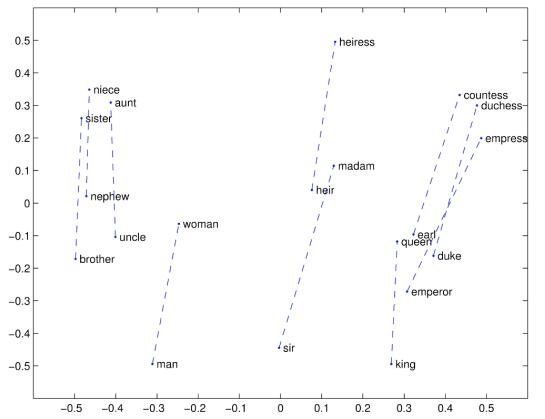
推论法,最著名的就是 king - man = queen - women

这里,距离的计算即是用到了向量的余弦相似度。
可视化结果:
5. 总结
这一节综合讨论了词向量方法中的统计方法与预测方法,从而引入斯坦福的Glove方法,skip-gram仅仅利用窗口内的共现性信息却没有充分利用到全局的共现值信息,而直觉上,该信息对词的表达以及词之间关联性有重大意义。不过,在实际任务中,两种模型的表现还要视结果而定,并无优劣之定论。