cs224n lecture 4 note: word win clf and nn
这节课介绍了根据窗口内上下文预测单词的分类问题,由此引入了softmax, hinge loss, cross entropy等函数,最后,详细推导了神经网络反向传播过程。
1. 分类
给定训练集
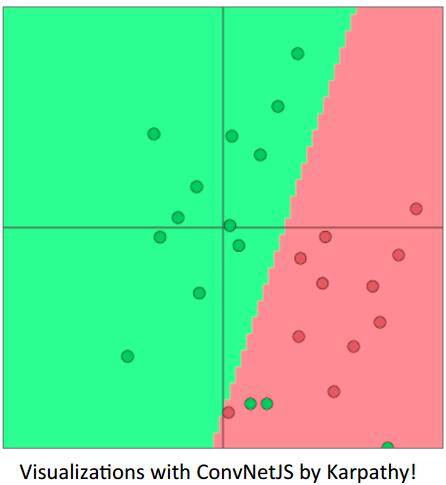
传统的机器学习算法,如逻辑回归,假设x是固定的,训练每个特征值(向量每一维度值)的权重,最终会得到如下图所示的决策边界。
Softmax
计算方法:取权值矩阵的某一行乘上输入向量,归一化得到该行对应类别的预测概率。
Cross-entropy
对于每个训练样本,我们的目标是最大化对应类别的概率,也就是最小化负log概率,log函数是凸函数并且使结果平滑,在损失中经常使用。
而这等效于交叉熵:
而分类任务中,y为one-hot向量,可见上述损失函数确实等效于计算预测值与真实值之间的交叉熵。
正则项
为了防止过拟合,通常要对参数正则化,来控制模型的复杂度,这样总的损失就变成了:
此外,课程以一个实例说明,当语料不大的时候,覆盖到的词有限,那么如果词向量再次参与训练,则会训练出只对少量数据拟合的参数,在测试时可能会导致本来语义相近的却没有出现在训练集中的词被映射到不同类型的语义空间中,导致错误。因此,要尤其注意,我们训练的参数应该具有良好的泛化性能,在小语料中要keep vectors static.
2. 分类任务
列举了softmax/lr分类的公式及效果,指出线性分类的局限性,从而引出具有强大非线性拟合能力的神经网络。
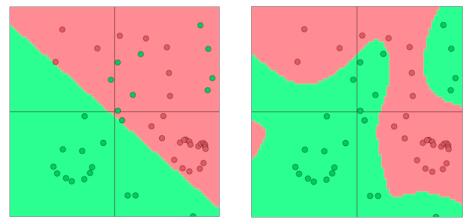
神经网络的每个结点输出前都进行一次非线性变化,这样的组合在实际任务中可以得到更好的决策边界,取得更好的效果。下图即为线性与非线性分类效果示意图。
反向传播
纯数学微分推导,和下节一起手写记录,值得注意的是每个结点都有激活函数,求导时不可忽略,这也在一定程度上决定了反向传播过程中间数据的复用性。
这节课对我来说难点就是向量内积到矩阵相乘的转化和单个结果转换成所有样本结果的简化,看的有点迷糊,不过,关键还是弄清楚每一步的size,size如果不对,是没法乘的,我在后续自己推的时候会加以注明。
3. 间隔最大化目标函数(hinge loss)
形式:
学过svm一定会对这个很清楚,$\Delta$ 控制软间隔,告诉模型,当正负得分差小于它时才会更新参数,而对于大于的样本,不再继续优化,也就是,专注于优化得分差在 $\Delta$附近的样本。
4. 总结
这一节和下一节主要是讲神经网络的反向传播过程,涉及很多公式的推导,往上粘贴一堆公式毫无意义,故打算和下节一起,手写推导出来。这周怎么没做呢??em…最近组会内容繁重,又即将开题答辩,时间很紧张…见谅见谅~~