cs224n lecture 6 note: dependency parsing
1. 前言
对于句法分析,我还算熟悉,毕设相关,不过,我是用的解析工具解析的,而这节课是介绍句法解析的发展和方法,对我有一个很好的补充。
2. 语言学的两种观点
为什么要研究语法?
显然,是为了让计算机能够理解自然语言,下面两种方法就体现了自然语言理解发展的过程。
第一种,就是短语结构文法(phrase structure grammar)或上下文无关文法(context-free grammars)。特点是用固定数量的规则分解句子为短语或单词,而规则,就是早期研究者致力研究的对象,短规则应该难度不大,但是整合规则到文法中就很复杂了,因为语言的主观性。下图是一个取自WSJ语料库的短语结构树示例:
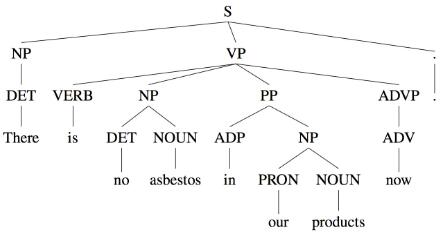
另一种就是依存结构,用单词之间的依存关系来表达语法。如果一个单词修饰另一个单词,则称该单词依赖于另一个单词。如下图所示:

其中,$a\stackrel{dep}{\longrightarrow}b$ 就表示b依赖于a,依赖关系是dep
3. 歧义
句法歧义
通过句法树可以表达歧义,没有被表示依赖关系的句子可能是存在歧义的,而一旦表达了依赖关系,对句子结构就有了确定的解读,往往就能表达确定的语义。看下图,不标注的话,可以表达scientists如何…,亦可表达study如何…,这是由于study与whale都既可做名词,也可做动词。一旦标注了依赖关系,那么就不存在歧义。
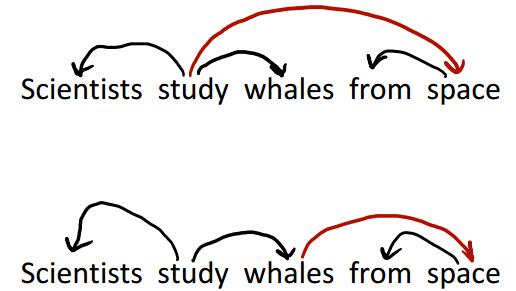
显然,我们在做依赖的时候,就会面临这个问题,我想这时候就要统计数据告诉我们答案。
依附歧义
学习依赖关系很重要的过程就是确定地把一个短语(介词短语、状语短语、分词短语、不定式等)依附到其他成分上去。比如下面的句子:
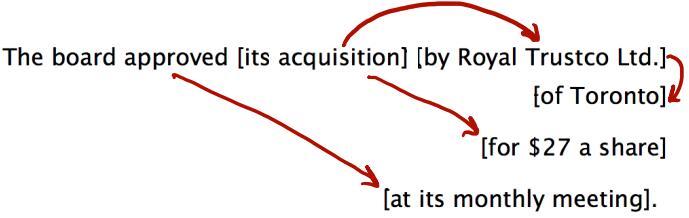
可见,不同的介词短语可能依赖于不同的词。对于n个短语来讲,组成的树形结构有$C_n = \frac{(2n)!}{(n+1)!n!}$种,这是Catalan数,呈指数级增长。
4. 标注数据集的崛起
上面也提到,上下文无关文法的短语规则是不难的,组合规则的语法工作似乎是研究的重点。但是,与此同时,人工构建有标注的树结构数据集这样的工作也在展开。起初,这看起来费时费力且用处不如语法工作。但构建好的树库会给我们以下几点好处:
- 虽然标注难度高,费时费力,但是标注好的数据可以在很多任务(如POS标注,NER,依存等)被复用。
- 构建了一个标准,供研究者评估性能。
- 很宝贵的标注数据集,可以应用机器学习方法。
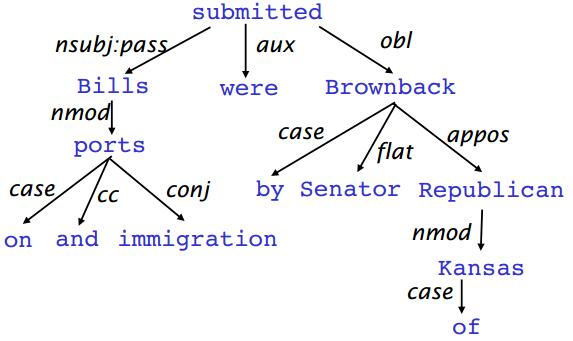
标注数据示例:

5. 依存文法和依存结构
依存句法标注了句子中单词的依赖关系,如果不标注,则是短语结构树的一种,我们通常研究依存句法树,因为相比于短语结构树,句法树标注更简单,解析准确率高。
句法分析可用特征
- 双词汇亲和
- 词语间距
- 中间词语
- 词语valency
依存句法分析
有几个约束条件:
- root只能被一个词依赖
- 无环
依存分析方法
- 动态规划。找出以某head结尾的字串对应的最可能的句法树。
- 最小生成树。从图中逐步删除不符合要求的边,直到成为一棵树。
- 基于转移的解析方法。主流方法,因为时间复杂度比较低(线性),效果比较好。
6. 基于转移的解析方法介绍
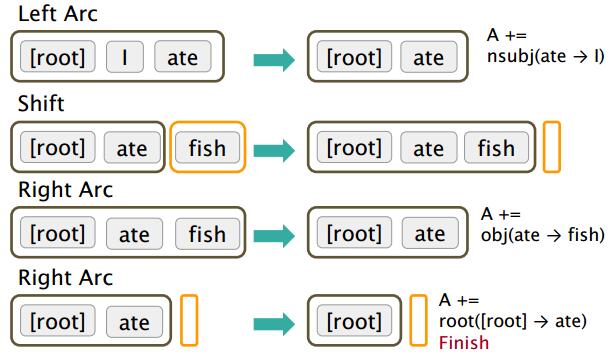
用栈保存即将处理的词,用buffer暂存句子的未处理词,就是个队列,按句子中的词序排列,先将buffer的词(b)入栈,再与原栈顶元素(a)判断操作,操作有以下三种:
- left arc: 当前焦点在b,得到b->a
- shift: 当前焦点由a变为b
- right arc: 当前焦点在b,得到a->b
算法如下图所示:

效果如下图所示:
7. 效果评估
分为UAS(不考虑标签,只考虑弧)和LAS(同时考虑标签和弧)
8. 特征表示
传统方法可应用的特征无非是栈和队列中单词、词性、依存关系组成的0-1向量,长且稀疏。而神经网络模型可以利用预训练得到的分布式稠密表示,运算更快,而且可以引入非线性,取得了很好的效果,减少了人力耗费,是现在的研究主流。
9. 总结
我的毕设模型就用到了解析结果,并结合了神经网络模型,我的体会是,依存关系能很好的表示句子的结构信息,能够帮助得到更富有表达的句子表示,另外,将传统的稀疏的特征信息,转换成稠密分布式向量是个很好的思路,像现在很多模型中的位置信息,指示信息等仍然在这样用。